Data from file name
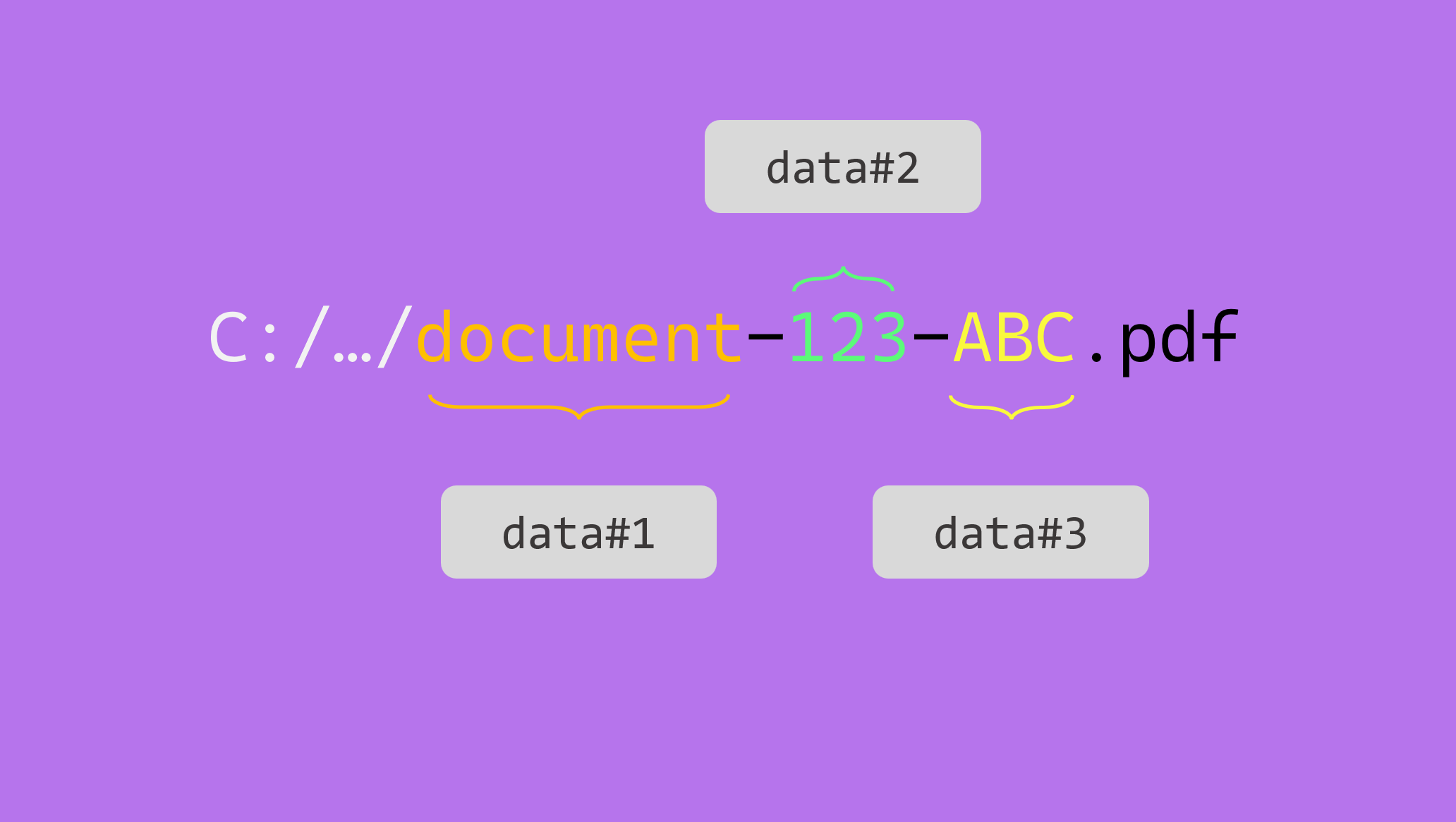
Times will happen when you will not be able to rely on side-file metadata documents to map onto the documents you are migrating. The data will be concatenated into the file name.
Fortunatelly with Fast2, there is still a possibility to parse this file name and pull out the required metadata. Last step would be to tight them down into the document dataset.
 Where do we come from ?¶
Where do we come from ?¶
For the educational aspect of this topic, let us consider a folder gathering several documents, all with the same format : <document-type>-<data1>-<data2>.
Our folder looks like this:
 Where to go ?¶
Where to go ?¶
At a glance, we are just 3 (major) steps away from having a PDF content in our punnet, with a basic dataset populated from the JSON metadata :
- Scan the parent folder and list all the documents with names to map,
- Get the document path, and isolate the file name
- Parse the file name and attach the metadata to the dataset. For this example, data will be mapped onto the document dataset.
 Way to go !¶
Way to go !¶
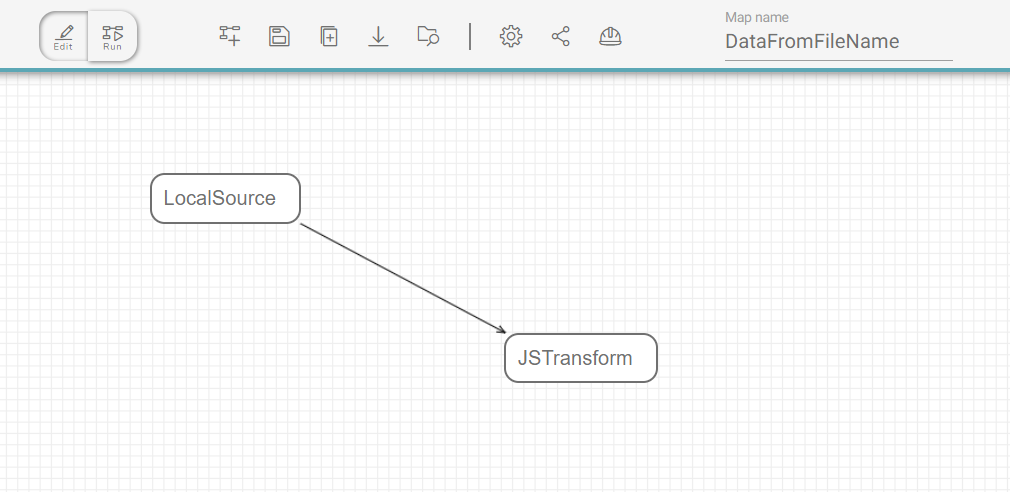
Inside Fast2, the map design is now pretty straightforward, given our ideas are rather clear in terms of the overall order of the operations.
The map is even quite close to the 3 steps detailed earlier. The LocalSource task just needs to be given the path of the folders to deal with. This task will also identify the file name and attach the metadata to the document dataset.
Then the JSTranform will retrieve the corresponding document path, and carry on with the data mapping.
That way, we end up with 4 tasks :
- LocalSource, to collect the documents from local storage,
- JSTranform, whose role will be to :
 parse the file name
parse the file name
 add the data to the dataset
add the data to the dataset
 JavaScript elaboration¶
JavaScript elaboration¶
Although the configuration of the first task can be easily guessed, the JSTranform final resulting script should look something like this :
punnet.getDocuments().forEach(function (doc) {
// (1)
var filenameWithoutExtension = doc
.getDataSet()
.getData("fileName")
.getValue()
.split(".")[0];
// (2)
var data = filenameWithoutExtension.split("-");
// (3)
doc.getDataSet().addData("document-type", "String", data[0]);
doc.getDataSet().addData("data1", "String", data[1]);
doc.getDataSet().addData("data2", "String", data[2]);
});
- Get the filename, and remove the extension
- Parse the filename with the separator character
 Attach the data
Attach the data
Head out now to the Run screen, start your campaign and just... enjoy !
 Result¶
Result¶
At the latest stage of your workflow, the document dataset is filled with the properties found in the JSON and integrated as metadata.
{
"punnetId": "document-123-ABC.pdf#1",
"documents": [
{
"documentId": "document-123-ABC.pdf",
"data": {
"absolutePath": "C:\\samples\\document-123-ABC.pdf",
"fileName": "document-123-ABC.pdf",
"absoluteParentPath": "C:\\samples",
"length": {
"value": "18700"
},
"lastModified": {
"value": "Mon Dec 27 14:10:47 CET 2021",
"type": "Date"
},
"document-type": "document",
"data1": "123",
"data2": "ABC"
},
"contents": {
"url": "C:\\samples\\document-123-ABC.pdf"
},
"folders": [...]
}
]
}
 Let's sum up¶
Let's sum up¶
We can bring this scenario further by mapping data from the parent folder(s). We would just need the document path, which can be retrieved easily, as explained in the advanced section of how to handle the JS Tranform task.
For a OS-proofed script (Linux or Windows have their own subtleties when it comes to paths), you may need to make sure the parsing is done correctly, by standardizing the folder-architecture-related special characters from the Windows \ to a regular /.
If this use-case echoes your early needs, other tasks can be tied to this map to reach a higher level of complexity characteristic of real-world migration projects.